
Έχοντας ασχοληθεί αναλυτικά με την έννοια των κανονικών εκφράσεων την περασμένη εβδομάδα, μπορούμε σήμερα να δημιουργήσουμε ένα project βασισμένο σε αυτές. Πάμε να δούμε τι θα χρειαστούμε, προκειμένου να γράψουμε ένα πρόγραμμα που να εντοπίζει και να εξάγει αριθμούς τηλεφώνου και διευθύνσεις email, από το κείμενο που του δίνουμε.
Προτάσεις συνεργασίας
Τα νέα άρθρα του PCsteps
Γίνε VIP μέλος στο PCSteps

Για να δείτε όλα τα μαθήματα Python από την αρχή τους, αλλά και τα επόμενα, αρκεί να κάνετε κλικ εδώ.
Μέθοδος findall()
Η findall() αποτελεί επέκταση της search() που είδαμε στο τελευταίο μάθημα.
Ενώ η search() επιστρέφει ένα αντικείμενο match της πρώτης εμφάνισης του μοτίβου μας στο κείμενο, η findall() θα επιστρέψει κάθε εμφάνιση. Δοκιμάζοντας στον IDLE τη search(), μπορούμε να το επαληθεύσουμε:
>>> phone_num_regex = re.compile(r'\d\d\d-\d\d\d\d\d\d\d')
>>> match_object = phone_num_regex.search('Home: 210-5553459 Work: 211-1234567')
>>> match_object.group()
'210-5553459'
Η findall(), απ' την άλλη, επιστρέφει μια λίστα από string, αν δεν υπάρχουν group στην κανονική έκφραση. Αν έχουμε group, τότε επιστρέφει μια λίστα από πλειάδες.
Για παράδειγμα, αν έχουμε ομάδες:
>>> phone_num_regex = re.compile(r'(\d\d\d)-(\d\d\d\d\d\d\d)')
>>> phone_num_regex.findall('Home: 210-5553459 Work: 211-1234567')
[('210', '5553459'), ('211', '1234567')]
Μέθοδος sub()
Εκτός από την εύρεση μοτίβων κειμένου, οι κανονικές εκφράσεις μπορούν να χρησιμοποιηθούν για την αντικατάσταση του υπάρχοντος κειμένου που εντοπίζουμε, με νέο.
Αν και δεν θα χρειαστούμε τη λειτουργία αυτή στο σημερινό project, θα μπορούσαμε εύκολα να το επεκτείνουμε με τη βοήθεια της sub().
Η συνάρτηση sub() λαμβάνει δύο ορίσματα. Το πρώτο είναι το string που θα αντικαταστήσει όλες τις εμφανίσεις του κειμένου, ενώ το δεύτερο είναι το string της κανονικής έκφρασης. Έτσι, το string που μας επιστρέφει η sub() είναι το κείμενο, με τις αντικαταστάσεις να έχουν υλοποιηθεί.
Για παράδειγμα:
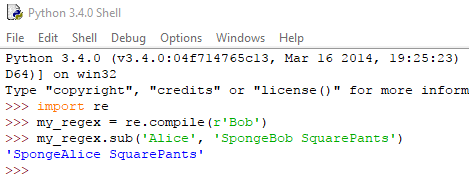
Μπορεί όμως να τύχει το ίδιο το κείμενο που αναζητούμε να πρέπει να υπάρχει και στο προς αντικατάσταση κείμενο. Σε αυτήν την περίπτωση, στο πρώτο όρισμα της sub() πληκτρολογούμε \1, \2, \3, κλπ, που μεταφράζεται ως: “Εισήγαγε το κείμενο της ομάδας 1, 2, 3, κλπ, κατά την αντικατάσταση.”
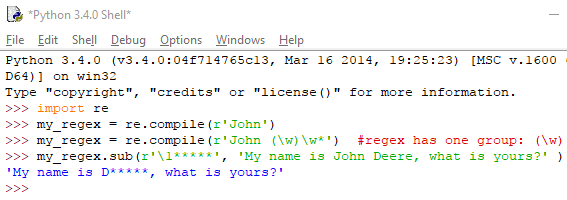
Ας πούμε, για παράδειγμα, ότι θέλουμε να αποκρύψουμε το όνομα και το επώνυμο οποιουδήποτε λέγεται ‘John'. Θα προσθέσουμε στην κανονική έκφραση, εκτός από το string, και μια ομάδα, πχ το \w, που σημαίνει έναν χαρακτήρα κειμένου.
Έπειτα θα περάσουμε στη sub() ως πρώτο όρισμα το r'\1*****', ώστε να εμφανίζεται μόνο το πρώτο group της regex μας, ακολουθούμενο από κάποιους αστερίσκους. Αφού ως πρώτο (και μοναδικό) group έχουμε τον χαρακτήρα \w, οποιοδήποτε ονοματεπώνυμο ξεκινάει με το string ‘John' θα αντικαθίσταται από τον πρώτο χαρακτήρα του επωνύμου.
Με άλλα λόγια, αυτό που θα δούμε είναι κάτι παρόμοιο με το εξής:
Πολύπλοκες regex
Οι κανονικές εκφράσεις είναι αρκετά απλές, αν και τα μοτίβα κειμένου που θέλουμε να εντοπίσουμε είναι απλά. Ωστόσο, πιο δύσκολα μοτίβα μπορεί να απαιτούν μεγάλες και αρκετά περίπλοκες εκφράσεις.
Για να κάνουμε τη ζωή μας πιο εύκολη, μπορούμε να πούμε στη συνάρτηση re.compile() να αγνοήσει τυχόν κενό χώρο ή σχόλια εντός του string της regex. Με αυτόν τον τρόπο, έχουμε τη δυνατότητα να την τακτοποιήσουμε καλύτερα, ώστε να μας διευκολύνει στο μάτι, αλλά και να εισάγουμε σχόλια.
Το μόνο που χρειάζεται είναι να περάσουμε ως δεύτερο όρισμα στη re.compile() τη μεταβλητή re.VERBOSE.
Αν δηλαδή έχουμε μια εχθρική για το μάτι έκφραση σαν αυτήν:
phone_regex = re.compile(r'((+\d{2}\s*)?(\d{3}|)(\s|-|\.)?\d{7})', re.VERBOSE)
…μπορούμε να την απλώσουμε σε περισσότερες γραμμές, κάνοντάς την πιο κατανοητή:
phone_regex = re.compile(r'''(
(+\d{2}\s*)? # κωδικός χώρας
(\d{3}|) # κωδικός περιοχής
(\s|-|\.)? # διαχωριστικό
\d{7} # τελευταία 7 ψηφία
)''', re.VERBOSE)
Υπενθυμίζουμε τη χρήση των τριών εισαγωγικών (”'), με την οποία μπορούμε να γράψουμε string σε περισσότερες από μία γραμμές.
Πρόγραμμα: Εξαγωγή τηλεφώνων και email
Έστω ότι μας έχει ανατεθεί η (βαρετή) εργασία της εύρεσης κάθε τηλεφωνικού αριθμού και διεύθυνσης email σε ένα έγγραφο ή σε μια ιστοσελίδα. Αν προσπαθήσουμε να ελέγξουμε χειροκίνητα ολόκληρη τη σελίδα, μάλλον θα χάσουμε πολύ χρόνο, και πιθανότατα να μας διαφύγει και κάποια καταχώρηση.
Αντίθετα, με ένα κατάλληλο πρόγραμμα που μπορεί να ελέγξει το πρόχειρο (clipboard) του υπολογιστή μας για αριθμούς και διευθύνσεις, η δουλειά μας θα απλοποιούνταν αρκετά.
Θα αρκούσε ένα Ctrl-A για να επιλέξουμε ολόκληρο το κείμενο, Ctrl-C για να το αντιγράψουμε στο πρόχειρο, και έπειτα μια εκτέλεση του προγράμματος. Το πρόγραμμα μπορεί να προχωρήσει στην αντικατάσταση του κειμένου του clipboard με μόνο τους αριθμούς και τις διευθύνσεις που βρήκε.
Όποτε ερχόμαστε αντιμέτωποι με ένα νέο project, καλό είναι πριν αρχίσουμε να γράφουμε τον κώδικα, να προσπαθούμε να σκεφτούμε τη συνολική εικόνα του προγράμματός μας. Να κατανοήσουμε, δηλαδή, ποιες είναι οι λειτουργίες που πρέπει να υλοποιήσουμε, προκειμένου να επιτευχθεί ο τελικός στόχος.
Για παράδειγμα, μπορούμε να πούμε ότι θέλουμε να γίνονται οι εξής δουλειές:
- Λήψη του κειμένου από το πρόχειρο
- Εύρεση όλων των τηλεφώνων και διευθύνσεων email στο κείμενο
- Επικόλλησή τους πίσω στο πρόχειρο
Στη συνέχεια, θα σκεφτούμε πώς μεταφράζονται οι εργασίες αυτές σε κώδικα. Με τον κώδικα θα χρειαστεί να κάνουμε τα ακόλουθα:
- Να κάνουμε αντιγραφή και επικόλληση string, κάτι που σημαίνει ότι θα χρειαστούμε το module pyperclip.
- Να δημιουργήσουμε δύο κανονικές εκφράσεις, μία για τηλέφωνα και μία για email.
- Να εντοπίζουμε όλες τις εμφανίσεις, όχι μόνο την πρώτη, και των δύο regex.
- Να μορφοποιήσουμε τα string που έχουν βρεθεί σε ένα ενιαίο string που θα κάνουμε επικόλληση.
- Να τυπώσουμε το κατάλληλο μήνυμα σε περίπτωση που δεν εντοπιστεί κάποιο τηλέφωνο ή email στο κείμενο.
Βάσει της λίστας αυτής, μπορούμε να κινηθούμε κατά τη συγγραφή του προγράμματος. Η ύπαρξή της διευκολύνει το έργο μας, καθώς κάθε βήμα είναι σχετικά απλό και αφορά πράγματα που (πάνω-κάτω) ξέρουμε πώς γίνονται στην Python.
Βήμα 1: Regex για αριθμό τηλεφώνου
Αρχικά, πρέπει να δημιουργήσουμε μια κανονική έκφραση για την αναζήτηση τηλεφωνικών αριθμών. Ανοίγουμε ένα νέο αρχείο στον editor, και γράφουμε:

Ας κάνουμε τη σύμβαση, για να αποφύγουμε πιο μπερδεμένες εκφράσεις, ότι ένας τηλεφωνικός αριθμός ξεκινάει – προαιρετικά – με τρία ψηφία περιοχής (όπως στην περίπτωση της Αθήνας).
Έπειτα ακολουθεί κενό (\s) ή παύλα (-) ή τελεία για να ενώσει τον κωδικό περιοχής με τον υπόλοιπο αριθμό.
Το τελευταίο στοιχείο της regex είναι τα επτά υπολειπόμενα ψηφία του αριθμού. Αν θέλουμε να προσθέσουμε σχόλια στην έκφρασή μας, για να βγάζουμε αργότερα άκρη τι έχουμε γράψει, χρησιμοποιούμε και τη verbose.
Τέλος, τοποθετούμε σχόλια στον κώδικά μας που αφορούν τα υπόλοιπα στοιχεία προς υλοποίηση.
Βήμα 2: Regex για διεύθυνση email
Θα χρειαστούμε επίσης μια regex για τον εντοπισμό διευθύνσεων email. Γράφουμε:
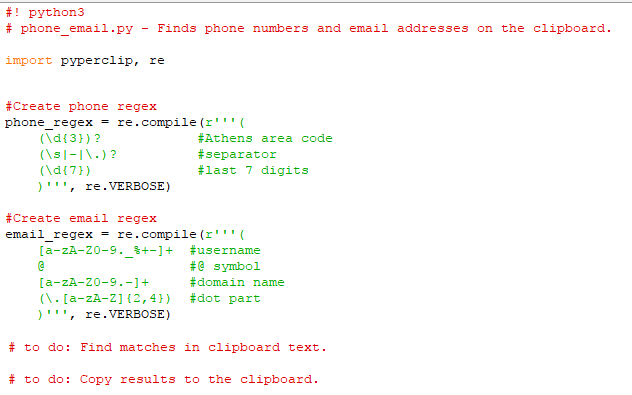
Το κομμάτι του email του οποίου τη σύνθεση επιλέγει ο χρήστης, αποτελείται από έναν ή περισσότερους χαρακτήρες, οι οποίοι δύνανται να είναι οι εξής: μικρά και κεφαλαία γράμματα, αριθμοί, τελεία, κάτω παύλα, σύμβολο επί τοις εκατό, συν, παύλα. Τα βάζουμε όλα αυτά μαζί σε μία τάξη χαρακτήρων: [a-zA-Z0-9._%+-].
Έπεται το domain, που διαχωρίζεται οπωσδήποτε από το προηγούμενο κομμάτι με το σύμβολο “@”. Ας θεωρήσουμε ότι τα domain μπορούν να απαρτίζονται μόνο από γράμματα, αριθμούς, τελεία, και παύλα: [a-zA-Z0-9.-].
Στο κλείσιμο της έκφρασης, μένει το τυπικό “τελεία-com” κομμάτι (το λεγόμενο domain υψηλού επιπέδου), που θεωρούμε ότι μπορεί να είναι από δύο έως τέσσερις χαρακτήρες γραμμάτων.
Βήμα 3: Εύρεση όλων των εμφανίσεων στο κείμενο
Τώρα που έχουμε ορίσει τις κανονικές εκφράσεις για τους αριθμούς τηλεφώνου και τις διευθύνσεις email, μπορούμε να αφήσουμε το module re της Python να κάνει τη βρώμικη δουλειά του εντοπισμού όλων εμφανίσεων στο πρόχειρο.
Με τη συνάρτηση pyperclip.paste() θα πάρουμε σε string το κείμενο που υπάρχει στο clipboard. Έπειτα, η μέθοδος findall() θα μας επιστρέψει μια λίστα από tuples (πλειάδες).
Προσθέτουμε στο πρόγραμμά μας:
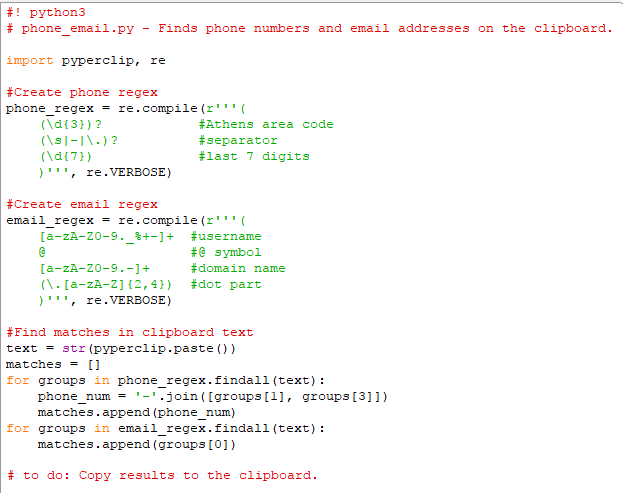
Υπάρχει μια πλειάδα για κάθε εμφάνιση, και κάθε πλειάδα περιέχει string για την κάθε ομάδα της κανονικής έκφρασης. Θυμόμαστε ότι το group 0 κάνει match ολόκληρη την κανονική έκφραση, οπότε αυτό το group της πλειάδας είναι που μας ενδιαφέρει.
Ας δούμε λίγο πιο αναλυτικά τι συμβαίνει στο νέο κομμάτι κώδικα που προσθέσαμε:
Αρχικά, χρησιμοποιούμε τη μεταβλητή matches, όπου θα αποθηκεύουμε σε μια λίστα όλες τις εμφανίσεις. Γι' αυτό και την αρχικοποιούμε ως άδεια λίστα, η οποία θα γεμίσει με τους επόμενους βρόχους for.
Για τις διευθύνσεις mail, προσθέτουμε (με την append()) στο τέλος της matches το group 0. Για τους αριθμούς τηλεφώνου δεν αρκεί ένα απλό append του group 0. Παρότι το πρόγραμμα ανιχνεύει αριθμούς σε διάφορες μορφές, εμείς θέλουμε να αποθηκεύονται σε μία σταθερή μορφή.
Η μεταβλητή phone_num περιέχει string που κατασκευάζεται από τα group 1 και 3, δηλαδή από τον κωδικό περιοχής και τα επόμενα επτά ψηφία.
Βήμα 4: Join σε ενιαίο string
Έχοντας πλέον τις διευθύνσεις και τους αριθμούς ως λίστα από string στη matches, θα πρέπει να τα τοποθετήσουμε στο πρόχειρο του υπολογιστή. Μιας και η pyperclip.copy() παίρνει ως όρισμα μόνο ένα string, και όχι λίστα από string, θα καλέσουμε τη μέθοδο join() στη matches.
Καλό είναι, επίσης, να προσθέσουμε μερικά print στον κώδικά μας, για να καταλάβουμε πιο εύκολα αν το πρόγραμμά μας δουλεύει σωστά. Τα print θα τυπώνουν ό,τι αναγνωρίσεις των μοτίβων μας βρίσκουμε, ενώ σε περίπτωση που δεν βρεθεί κανένα, το πρόγραμμα θα τυπώνει το αντίστοιχο μήνυμα.
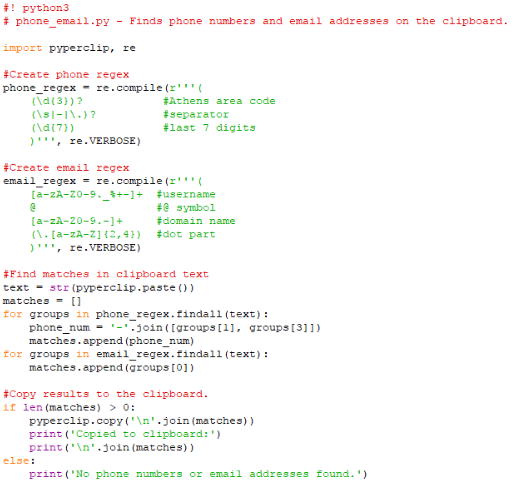
Εκτέλεση προγράμματος
Πριν τρέξουμε το πρόγραμμα, μπορούμε να επισκεφτούμε μια ενδεικτική σελίδα στον browser μας, και πατώντας Ctrl+A και, στη συνέχεια, Ctrl+C, να αντιγράψουμε το κείμενο στο clipboard.
Για τις ανάγκες του παραδείγματος, εμείς επισκεφθήκαμε τη σελίδα επικοινωνίας του Υπουργείου Οικονομικών, η οποία περιέχει μπόλικα τηλέφωνα και διευθύνσεις ηλεκτρονικού ταχυδρομείου.
Εκτελώντας το πρόγραμμα, θα πάρουμε μια μεγάλη εκτύπωση που ξεκινάει με τα τηλέφωνα που έχουν βρεθεί:
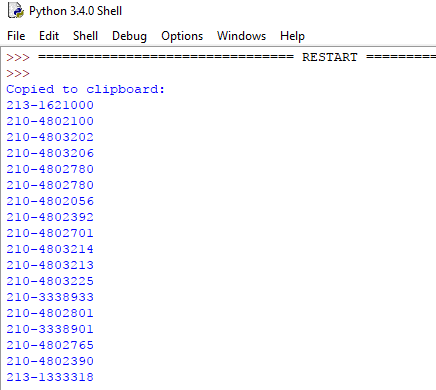
…και καταλήγει με τα email:

Στο επόμενο μάθημα για τον προγραμματισμό Python
Θα μάθουμε πώς γίνεται να χρησιμοποιήσουμε την Python για να δημιουργήσουμε, να διαβάσουμε, και να αποθηκεύσουμε αρχεία στον σκληρό μας δίσκο.
Σας άρεσε το σημερινό μάθημα για τον προγραμματισμό Python?
Πώς σας φάνηκε το project αυτής της εβδομάδας? Για τυχόν απορίες, γράψτε μας στα σχόλια.
Για να δείτε όλα τα μαθήματα Python από την αρχή τους, αλλά και τα επόμενα, αρκεί να κάνετε κλικ εδώ.
 Save as PDF
Save as PDF



