
Σήμερα θα ασχοληθούμε με την αναζήτηση κειμένου, και πιο ειδικά με την αναζήτηση μοτίβων κειμένου. Θα δούμε αρχικά την αναζήτηση χωρίς κανονικές εκφράσεις. Στη συνέχεια θα δούμε πώς οι κανονικές εκφράσεις μας βοηθούν να γράψουμε πιο καθαρό κώδικα, ενώ θα μάθουμε και άλλες λειτουργίες, όπως η αντικατάσταση string και η δημιουργία των δικών μας τάξεων χαρακτήρων.
Προτάσεις συνεργασίας
Τα νέα άρθρα του PCsteps
Γίνε VIP μέλος στο PCSteps

Για να δείτε όλα τα μαθήματα Python από την αρχή τους, αλλά και τα επόμενα, αρκεί να κάνετε κλικ εδώ.
Ίσως είμαστε συνηθισμένοι να πραγματοποιούμε αναζήτηση πατώντας CTRL+F και πληκτρολογώντας τη λέξη που ψάχνουμε.
Με τις κανονικές εκφράσεις (regular expressions – regex) μπορούμε να πάμε την αναζήτησή μας ένα βήμα παραπέρα, αφού μας επιτρέπουν να ορίσουμε ένα μοτίβο κειμένου προς αναζήτηση (match).
Εύρεση μοτίβων κειμένου χωρίς κανονικές εκφράσεις
Μπορεί να μην γνωρίζουμε τον ακριβή αριθμό μιας επιχείρησης, αλλά αν ξέρουμε ότι έχουν την έδρα τους στη Θεσσαλονίκη, για παράδειγμα, μπορούμε να υποθέσουμε κάποια στοιχεία για τον αριθμό αυτόν.
Έστω, λοιπόν, ότι θέλουμε να βρούμε έναν τηλεφωνικό αριθμό Θεσσαλονίκης σε ένα string. Ας θεωρήσουμε πως γνωρίζουμε ότι το μοτίβο είναι το εξής: τέσσερις αριθμοί, ακολουθούμενοι από μία παύλα, και μετά από άλλους έξι αριθμούς. Για παράδειγμα:
2310-521010
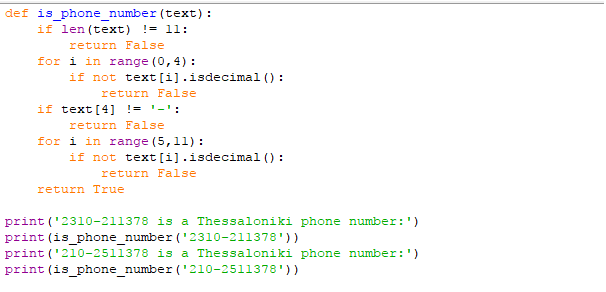
Με τη συνάρτηση is_phone_number() ελέγχουμε αν το string ταιριάζει με το μοτίβο αυτό, επιστρέφοντας True ή False. Γράφουμε στον editor μας:
Και το αποτέλεσμα της εκτύπωσης είναι:
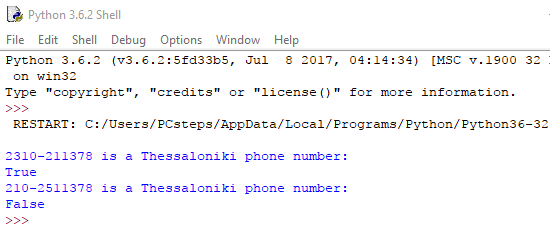
Η συνάρτηση ουσιαστικά ελέγχει κάθε κομμάτι του string, για να δει αν εκεί που περιμένουμε αριθμό υπάρχει αριθμός, εκεί που περιμένουμε παύλα υπάρχει παύλα, κοκ.
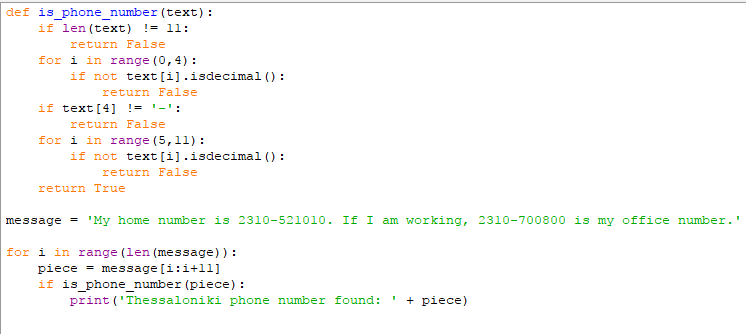
Αν, τώρα, το string μας είναι μεγαλύτερο, θα πρέπει να προσθέσουμε ακόμα περισσότερο κώδικα:
Εκτελώντας τον, θα δούμε τα παρακάτω:
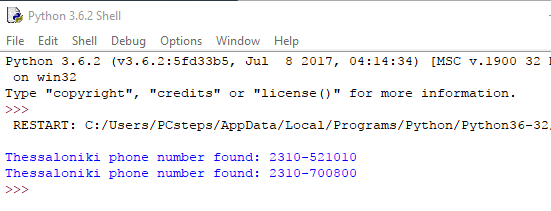
Σε κάθε επανάληψη του βρόχου, ελέγχουμε ένα νέο κομμάτι 11 χαρακτήρων από το συνολικό string, για να δούμε αν ταιριάζει στο μοτίβο μας.
Αν και το string στο παράδειγμά μας είναι σχετικά μικρό, ίσως κληθούμε να κάνουμε την ίδια δουλειά και για string εκατομμυρίων χαρακτήρων. Σε αυτές τις περιπτώσεις, οι κανονικές εκφράσεις θα μας βοηθήσουν σημαντικά.
Εύρεση μοτίβων κειμένου με κανονικές εκφράσεις
Το πρόγραμμα της προηγούμενης ενότητας βρίσκει το μοτίβο που θέλουμε. Τι θα συμβεί όμως αν το νούμερο είναι γραμμένο με άλλη μορφή: 2310 521010 ή (2310)521010? Η συνάρτησή μας θα αποτύχει να το θεωρήσει έγκυρο.
Μπορούμε να γλιτώσουμε την εισαγωγή επιπλέον κώδικα για να συμπεριλάβουμε και άλλες περιπτώσεις, με έναν πιο εύκολο τρόπο.
Οι κανονικές εκφράσεις ή regex, δίνουν μια περιγραφή για το μοτίβο κειμένου που μας ενδιαφέρει. Για παράδειγμα, το “\d” σε μια regex αντιπροσωπεύει αριθμό, από το 0 έως το 9. Έτσι, η regex:
\d\d\d\d-\d\d\d\d\d\d
σημαίνει ένα string τεσσάρων αριθμών, ακολουθούμενων από μια παύλα και από άλλους έξι αριθμούς.
Όμως οι κανονικές εκφράσεις μας προσφέρουν πολύ περισσότερες δυνατότητες. Ένας αριθμός σε άγκιστρα μετά από ένα μοτίβο, σημαίνει: “Ψάξε το μοτίβο αυτό τρεις φορές”. Η προηγούμενη έκφραση, δηλαδή, θα μπορούσε να γραφτεί πιο σύντομα:
\d{4}-\d{6}
Δημιουργία αντικειμένων Regex
Όλες οι συναρτήσεις regex της Python βρίσκονται στο module re. Το εισάγουμε με τη γνωστή δήλωση:
>>> import re
Για να δημιουργήσουμε ένα αντικείμενο regex, θα χρειαστούμε τη re.compile(). Περνώντας της το string που αναπαριστά την κανονική μας έκφραση, αυτό που μας επιστρέφει είναι ένα αντικείμενο regex.
Στο παράδειγμά μας, για να αποθηκεύσουμε ως αντικείμενο το μοτίβο τηλεφωνικών αριθμών Θεσ/νίκης, μπορούμε να γράψουμε:
>>> import re >>> phone_num_regex = re.compile(r'\d\d\d\d-\d\d\d\d\d\d')
Παρατηρούμε ότι επιλέξαμε να χρησιμοποιήσουμε raw string ως όρισμα στη συνάρτηση, καθώς το backslash απαντάται συχνά στα string των κανονικών εκφράσεων. Από το να κάνουμε escape, λοιπόν, ένα-ένα κάθε backslash του, είναι προτιμότερη η χρήση raw string.
Για να αξιοποιήσουμε, τώρα, το αντικείμενο που δημιουργήσαμε, θα χρησιμοποιήσουμε τη μέθοδο search(). Στη search() περνάμε ένα string και αυτή επιστρέφει ένα αντικείμενο Match, αν το μοτίβο υπάρχει στο string, και None σε διαφορετική περίπτωση.
Έπειτα, με τη μέθοδο group() μπορούμε να πάρουμε το ίδιο το κείμενο στο οποίο βρέθηκε το string που θέλουμε. Για παράδειγμα:
>>> phone_num_regex = re.compile(r'\d\d\d\d-\d\d\d\d\d\d')
>>> match_object = phone_num_regex.search('My number is 2310-521010')
>>> print('Phone number found: ' + match_object.group())
Phone number found: 2310-521010
Αποθηκεύουμε το αντικείμενο Match που επιστρέφει η .search() στη match_object και, εφόσον γνωρίζουμε ότι δεν περιέχει τιμή None (αφού το μοτίβο υπάρχει στο string), καλούμε την .group() για να λάβουμε το κείμενο που ταυτοποιήθηκε.
Επισκόπηση της διαδικασίας
Ας συνοψίσουμε, λοιπόν, τη διαδικασία με την οποία χρησιμοποιούμε τις κανονικές εκφράσεις για την εύρεση μοτίβων κειμένου, στα εξής βήματα:
- Εισάγουμε το module των κανονικών εκφράσεων (import re).
- Δημιουργούμε ένα αντικείμενο regex με τη συνάρτηση re.compile, προσέχοντας να χρησιμοποιήσουμε raw string ως όρισμα.
- Περνάμε ως όρισμα στη μέθοδο .search() του αντικειμένου regex το string που θέλουμε να αναζητήσουμε. Αυτή επιστρέφει ένα αντικείμενο Match.
- Καλούμε τη μέθοδο .group() του αντικειμένου Match για να ανακτήσουμε το κείμενο που εντοπίστηκε.
Τώρα που γνωρίζουμε τα βασικά βήματα για τη δημιουργία και εύρεση αντικειμένων regex στην Python, είμαστε έτοιμοι να προσπαθήσουμε πιο πολύπλοκες εργασίες.
Ομαδοποίηση με παρενθέσεις
Έστω ότι θέλουμε να διαχωρίσουμε τον κωδικό περιοχής από τον υπόλοιπο τηλεφωνικό αριθμό. Προσθέτοντας παρενθέσεις μπορούμε να δημιουργήσουμε ομάδες στη regex μας:
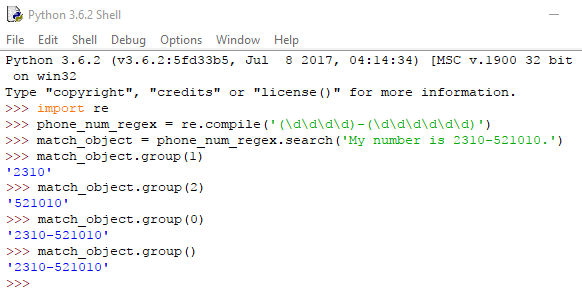
(\d\d\d\d)-(\d\d\d\d\d\d)
Στη συνέχεια, έχουμε τη δυνατότητα να ανακτήσουμε κείμενο μόνο από μια ομάδα, με τη μέθοδο group(). Το πρώτο σύνολο που βρίσκεται εντός παρενθέσεων αποτελεί το group(1), το δεύτερο το group(2), κοκ. Περνώντας το 0 ή κενό στην group(), θα πάρουμε ολόκληρο το κείμενο.
Μπορούμε να γράψουμε στον IDLE:
Αν τώρα θέλουμε να ανακτήσουμε μαζί όλες τις ομάδες που έχουμε δημιουργήσει, χρησιμοποιούμε την groups() (προσοχή στον πληθυντικό: -s). Αυτή μας επιστρέφει μια πλειάδα με τα σύνολα, που όλα μαζί μας δίνουν το εντοπισμένο κείμενο.
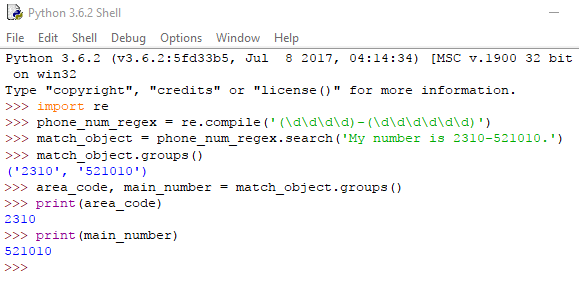
Αφού η groups() μας επιστρέφει πλειάδα, χρησιμοποιήσαμε την πολλαπλή ανάθεση για να αποθηκεύσουμε κάθε group σε διαφορετική μεταβλητή.
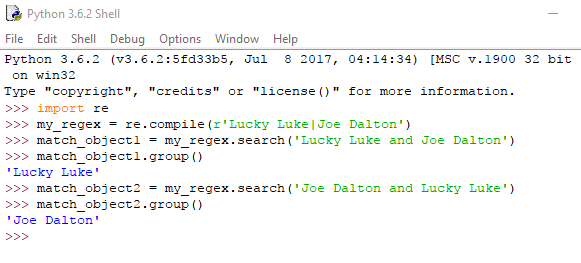
Αν θέλουμε να χρησιμοποιήσουμε μια regex για την εύρεση περισσότερων του ενός μοτίβου, θα χρειαστούμε την κάθετο | (pipe). Ως συνήθως, σε περίπτωση που υπάρχουν όλα τα μοτίβα στο string που ελέγξαμε, θα μας επιστραφεί αυτό που βρέθηκε πρώτο.
Ας δούμε τα παραπάνω σε ένα παράδειγμα:
Επιλεκτική αναγνώριση μοτίβου
Μερικές φορές μπορεί να έχουμε ένα μοτίβο που θέλουμε να ταιριάζει στο string μόνο προαιρετικά. Δηλαδή η regex μας θέλουμε να ταυτοποιήσει κάποιο κείμενο, είτε αυτό το κομμάτι υπάρχει στο string, είτε όχι.
Με τον χαρακτήρα του ερωτηματικού (?) ορίζουμε το group που προηγείται ως προαιρετικό κομμάτι του μοτίβου. Για παράδειγμα:
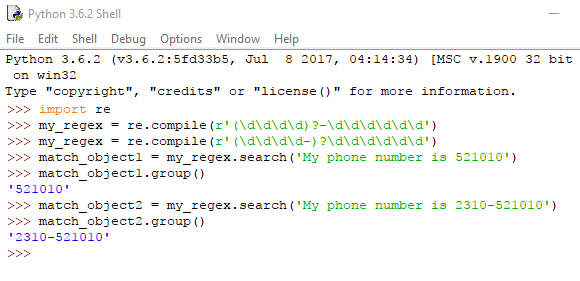
Το group που υπάρχει πριν από το ερωτηματικό μπορεί να αγνοηθεί κατά την αναζήτηση για το μοτίβο κειμένου που μας ενδιαφέρει.
Βάζοντας τον κωδικό περιοχής στη θέση αυτήν, λέμε στη search() να εντοπίσει τηλεφωνικούς αριθμούς, είτε σε αυτούς περιλαμβάνεται κωδικός περιοχής είτε όχι.
Επιλογή πλήθους εμφανίσεων
Με τη βοήθεια κάποιων ειδικών χαρακτήρων, μπορούμε να εξειδικεύσουμε περαιτέρω την αναζήτηση μοτίβων με τις κανονικές εκφράσεις.
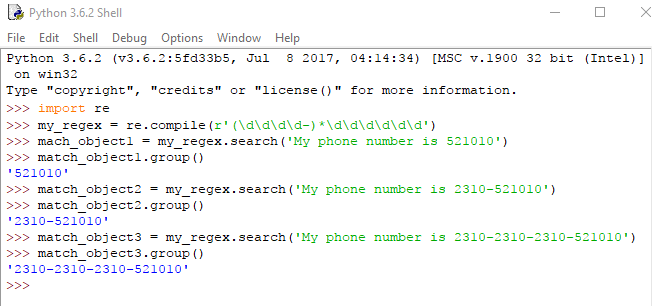
Καμία ή περισσότερες (*)
Το σύμβολο του αστερίσκου (*) σημαίνει εμφάνιση “καμία ή παραπάνω φορές” για την ομάδα η οποία προηγείται. Δηλαδή η ομάδα αυτή προαιρετικά μπορεί να υπάρχει στο κείμενο σε οποιοδήποτε αριθμό εμφανίσεων ή και να απουσιάζει τελείως.
Ας συνεχίσουμε με το προηγούμενο παράδειγμα:
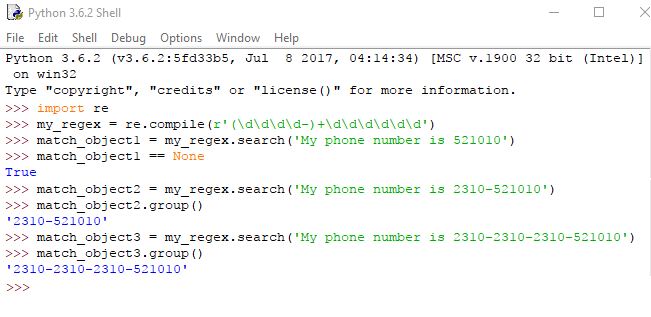
Μία ή περισσότερες (+)
Ενώ με τον αστερίσκο λέμε καμία ή περισσότερες εμφανίσεις, με το σύμβολο της άθροισης (+), διασφαλίζουμε ότι έστω μία φορά η ομάδα που προηγείται του συμβόλου πρέπει να περιέχεται στο κείμενο.
Μπορούμε να δοκιμάσουμε στον IDLE το παράδειγμά μας και να συγκρίνουμε με την regex με τον αστερίσκο της προηγούμενης ενότητας:
Συγκεκριμένο πλήθος ({})
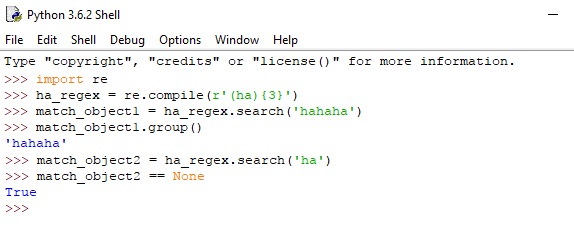
Αν έχουμε μία ομάδα που επιθυμούμε να επαναλαμβάνεται στο κείμενο για συγκεκριμένο πλήθος εμφανίσεων, θα χρησιμοποιήσουμε έναν αριθμό μέσα σε άγκιστρα.
Για παράδειγμα, η regex (ha){3} θα εντοπιστεί στο string ‘hahahaha' αλλά όχι και στο ‘haha', αφού το δεύτερο έχει μόνο δύο επαναλήψεις της ομάδας (ha).
Έχουμε, ακόμη, τη δυνατότητα να ορίσουμε ένα εύρος επαναλήψεων, αντί για συγκεκριμένο αριθμό, γράφοντας τον ελάχιστο και (μετά από κόμμα) τον μέγιστο του εύρους μέσα στα άγκιστρα.
Για παράδειγμα, η regex (ha){2,4} θα αναγνωριστεί στα string ‘haha', ‘hahaha' και ‘hahahaha'.
Αφήνοντας τον έναν από τους δύο αριθμούς κενό, δηλώνουμε διάστημα ανοιχτό, δηλαδή πλήθος επαναλήψεων μεγαλύτερο ή μικρότερο από έναν αριθμό. Έτσι, το (ha){,5} σημαίνει από καμία μέχρι και πέντε εμφανίσεις, ενώ το (ha){2,} δύο ή περισσότερες.
Με τα άγκιστρα μειώνουμε αρκετά το μήκος των regex μας. Οι εκφράσεις:
(ha){4}
(ha)(ha)(ha)(ha)
είναι ταυτόσημες, όπως και οι:
(ha){3,5}
((ha)(ha)(ha))|((ha)(ha)(ha)(ha))|(ha)(ha)(ha)(ha)(ha))
Ας δούμε ένα παράδειγμα χρήσης αγκίστρων και στον IDLE:
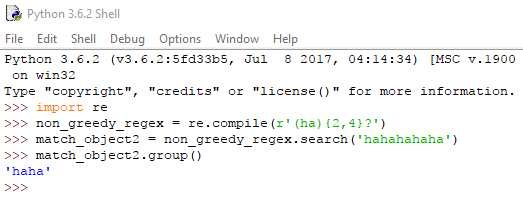
Σημείωση: Διαπιστώνουμε ότι όταν χρησιμοποιούμε εύρος, πχ re.compile(r'(ha){2,4}'), η group() που καλούμε στο match αντικείμενό μας θα επιστρέψει πάντα το μεγαλύτερο string. Δηλαδή:
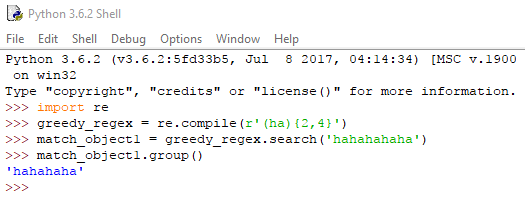
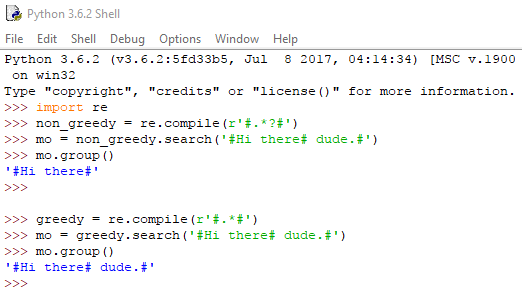
Αυτό συμβαίνει γιατί οι regex της Python είναι από προεπιλογή άπληστες (greedy). Σε περίπτωση εντοπισμού του μοτίβου περισσότερες από μία φορές, θα επιλεχθεί το μεγαλύτερο string εξ αυτών.
Αν θέλουμε να επιστρέφεται το μικρότερο δυνατό string, αρκεί να προσθέσουμε ένα ερωτηματικό αμέσως μετά τα άγκιστρα:
Τάξεις χαρακτήρων
Μέχρι στιγμής, στα παραδείγματά μας χρησιμοποιούμε τον χαρακτήρα \d, ο οποίος όπως μάθαμε δηλώνει το αριθμητικό ψηφίο. Θα μπορούσαμε δηλαδή να πούμε ότι ο \d είναι η συντομογραφία της έκφρασης (0|1|2|3|4|5|6|7|8|9|).
Υπάρχουν και άλλες τέτοιες τάξεις χαρακτήρων που αποτελούν συντομότερη έκδοση μεγαλύτερων εκφράσεων.

Οι τάξεις χαρακτήρων είναι κι αυτές ένα εργαλείο που μας επιτρέπει να μειώνουμε τις κανονικές εκφράσεις. Η τάξη [0-5], που θα ταιριάξει αριθμούς μόνο από το 0 έως το 5, είναι πολύ πιο σύντομη σε σύγκριση με την (0|1|2|3|4|5).
Δημιουργία νέων τάξεων χαρακτήρων
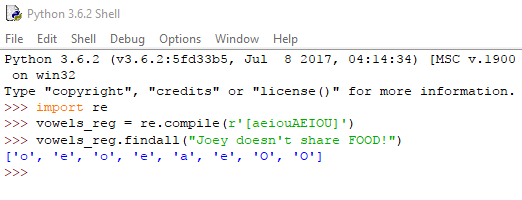
Συχνά θα τύχει να θέλουμε να βρούμε μια φράση, για την οποία οι διαθέσιμες τάξεις χαρακτήρων είναι πιο γενικές από όσο μας χρειάζεται. Παραδείγματος χάριν, αν στην κανονική μας έκφραση ψάχνουμε οποιοδήποτε φωνήεν, μικρό ή μεγάλο.
Σε τέτοιες περιπτώσεις, ορίζουμε τις δικές μας τάξεις, με τη χρήση αγκύλων. Ας το δούμε στην πράξη με τη βοήθεια της findall(), που επιστρέφει όλες τις εμφανίσεις της regex μας (θα αναφερθούμε αναλυτικότερα την ερχόμενη εβδομάδα):
Μπορούμε, ακόμη, να συμπεριλάβουμε διαστήματα γραμμάτων ή αριθμών με τη χρήση της παύλας. Η τάξη χαρακτήρα [a-zA-z0-9] θα βρει όλα τα μικρά γράμματα, τα κεφαλαία γράμματα, και τους αριθμούς.
Να σημειωθεί ότι εντός των αγκύλων, τα κανονικά σύμβολα regex δεν ερμηνεύονται με τον κλασικό τρόπο. Αυτό σημαίνει ότι δεν χρειάζεται να κάνουμε escape με backslash τα σύμβολα: ., *, ?, (, ).
Για παράδειγμα η τάξη [0-5.] θα εντοπίσει ψηφία από το 0 έως το 5 και μία τελεία. Δεν χρειάζεται να το γράψουμε ως [0-5\.].
Τέλος, μπορούμε να ορίσουμε αρνητική τάξη με τον χαρακτήρα ^, αν θέλουμε να κάνουμε αναζήτηση για χαρακτήρες που δεν περιέχονται στο κείμενο. Πάμε στον IDLE:
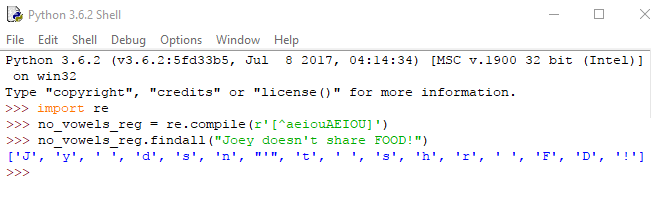
Πλέον γίνεται εύρεση κάθε χαρακτήρα που δεν είναι φωνήεν.
Ειδικοί χαρακτήρες
Μέσα στις κανονικές εκφράσεις μπορούμε να εισάγουμε κάποια σύμβολα που θα εξειδικεύσουν περισσότερο την αναζήτησή μας.
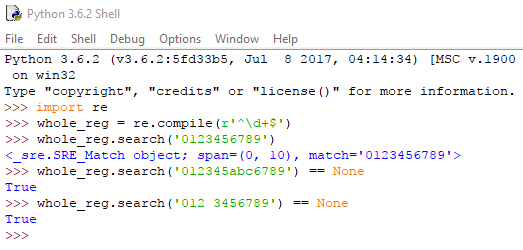
Ύψωση (^) και δολάριο ($)
Βάζοντας το σύμβολο της ύψωσης (^) στην αρχή μιας regex, δηλώνουμε ότι πρέπει να γίνει εύρεση του μοτίβου στην αρχή του κειμένου στο οποίο αναζητούμε. Αντίστοιχα, βάζοντας το σύμβολο του δολαρίου ($) στο τέλος μιας regex, δηλώνουμε ότι το κείμενο πρέπει να τελειώνει με αυτό το μοτίβο.
Ας δούμε ένα παράδειγμα:
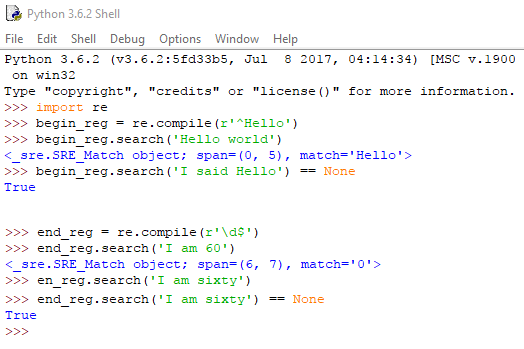
Αν χρησιμοποιήσουμε μαζί τα ^ και $, θα πρέπει ολόκληρο το string να ταιριάζει με την regex μας, και όχι απλά να την περιέχει.
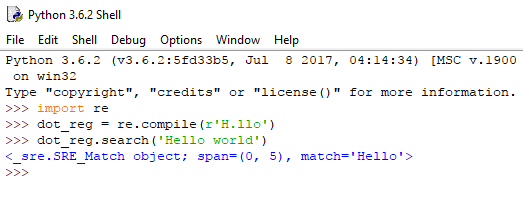
Τελεία (.)
Η τελεία είναι το σύμβολο-πασπαρτού, που μπορεί να αντιπροσωπεύσει οποιονδήποτε χαρακτήρα. Βάζοντάς το στη regex μας, θα γίνει αναγνώριση της φράσης στο κείμενο, όποιος χαρακτήρας και αν βρίσκεται στη θέση της τελείας.
Εξαίρεση αποτελεί ο χαρακτήρας newline, δηλαδή της αλλαγής γραμμής.
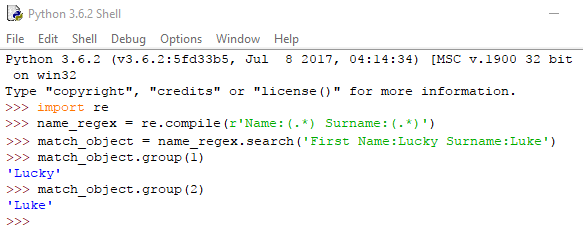
Τελεία – αστερίσκος (.*)
Κάποιες φορές θα χρειαστεί να ψάξουμε κάθε πιθανό αποτέλεσμα μέσα στο μοτίβο μας. Για παράδειγμα, αν θέλουμε να εντοπίσουμε το string ‘Name: ‘, ακολουθούμενο από οποιοδήποτε κείμενο και έπειτα το string ‘Surname: ‘, μαζί με άλλο ένα κομμάτι κειμένου.
Εδώ θα χρησιμοποιήσουμε τον συνδυασμό τελείας και αστερίσκου, για να δηλώσουμε το “οποιοδήποτε” αποτέλεσμα που περιμένουμε. Η τελεία, όπως είδαμε, αντιπροσωπεύει κάθε πιθανό χαρακτήρα, πλην του newline, ενώ ο αστερίσκος σημαίνει “κανέναν ή περισσότερους από τον αμέσως προηγούμενο χαρακτήρα”.
Και στην προκειμένη περίπτωση η regex είναι greedy, επιστρέφει δηλαδή όσο το δυνατόν περισσότερο κείμενο μπορεί.
Και πάλι με το σύμβολο του ερωτηματικού μπορούμε να αναιρέσουμε τη λειτουργία αυτή, και να επιστρέφεται όσο το δυνατόν λιγότερο κείμενο. Η διαφορά μπορεί να γίνει πιο ξεκάθαρη με ένα ακόμη παράδειγμα:
Τελεία και newline
Μπορούμε να υποχρεώσουμε την τελεία να κάνει match τον χαρακτήρα νέας γραμμής. Αρκεί να περάσουμε την re.DOTALL ως δεύτερο όρισμα στη re.compile(), και ο χαρακτήρας της τελείας θα αναγνωρίζεται σε οποιονδήποτε χαρακτήρα, συμπεριλαμβανομένου του newline.
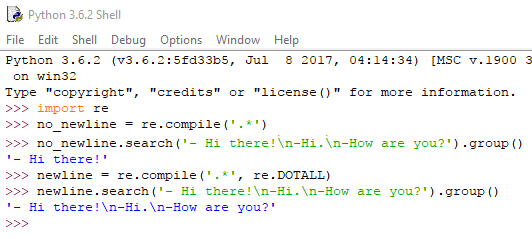
Βλέπουμε ότι στην πρώτη περίπτωση, το string που επέστρεψε είναι μόνο η πρώτη γραμμή μέχρι το newline, ενώ στη δεύτερη ανακτήσαμε ολόκληρο το κείμενο.
Επισκόπηση συμβόλων regex
Επειδή μάλλον πήξαμε από τα πολλά σύμβολα που αναφέρθηκαν στο σημερινό μάθημα, καλό είναι να τα συγκεντρώσουμε όλα μαζί σε έναν πίνακα, μαζί με μια συνοπτική περιγραφή.

Στο επόμενο μάθημα για τον προγραμματισμό Python
Θα εφαρμόσουμε τα όσα μάθαμε σήμερα στην πράξη με ένα project, βλέποντας βήμα-βήμα όλη τη διαδικασία, από την προετοιμασία μέχρι και την εκτέλεση. Αν χρειαστεί να θυμηθούμε τη λειτουργία κάποιου συμβόλου, μπορούμε να ανατρέχουμε στον πίνακα της προηγούμενης ενότητας.
Σας άρεσε το σημερινό μάθημα για τον προγραμματισμό Python?
Περιμένουμε να ακούσουμε απορίες ή προβλήματα, αλλά και τις δικές σας ιδέες για κάποιο πρόγραμμα.
Για να δείτε όλα τα μαθήματα Python από την αρχή τους, αλλά και τα επόμενα, αρκεί να κάνετε κλικ εδώ.




